Lumine: How a 7B Model Plays Genshin Impact for 5 Hours
My 'oh shit' moment in AI, the moment that its capabilities had me annoying my non-technical friends, was when the OpenAI Five (agents) beat the (human) world champions in Dota 2, back in 2019. Before that, AlphaGo was impressive but kind of academic and distant, like a chess solver. But to this day, generalist real-time gaming agents are still pretty lacklustre.
So, when this paper 'Lumine' came out, detailing a recipe for a general agent that can in real time use keyboard and mouse controls to play Genshin Impact's story mode for 5 hours and even play other games, I wanted to comb through the report and write up some thoughts.
It's a model that plays video games like humans do – with keyboard and mouse controls, Genshin Impact in particular but not exclusively – across a long time horizon of several hours. It uses raw pixels from the game as perceptual inputs, processing them along with its own reasoning chains and previous actions at 5Hz, while outputting action chains at up to 30Hz. It even generalises across games, picking up skills like UI interaction, world traversal, puzzle solving, NPC interaction, and combat that requires decent dexterity like aiming.
How it Works
Lumine is based on Qwen2-VL-7B, which it builds on in three main stages:
- Pre-training: ~1,700 hours of Genshin Impact video with accompanying control data (keyboard and mouse inputs) for continued pretraining of the base model
- Instruction tuning: 200 hours of instruction-labelled data with actions
- Reasoning: Training on reasoning data, producing a model that optionally outputs reasoning tokens alongside keyboard and mouse actions
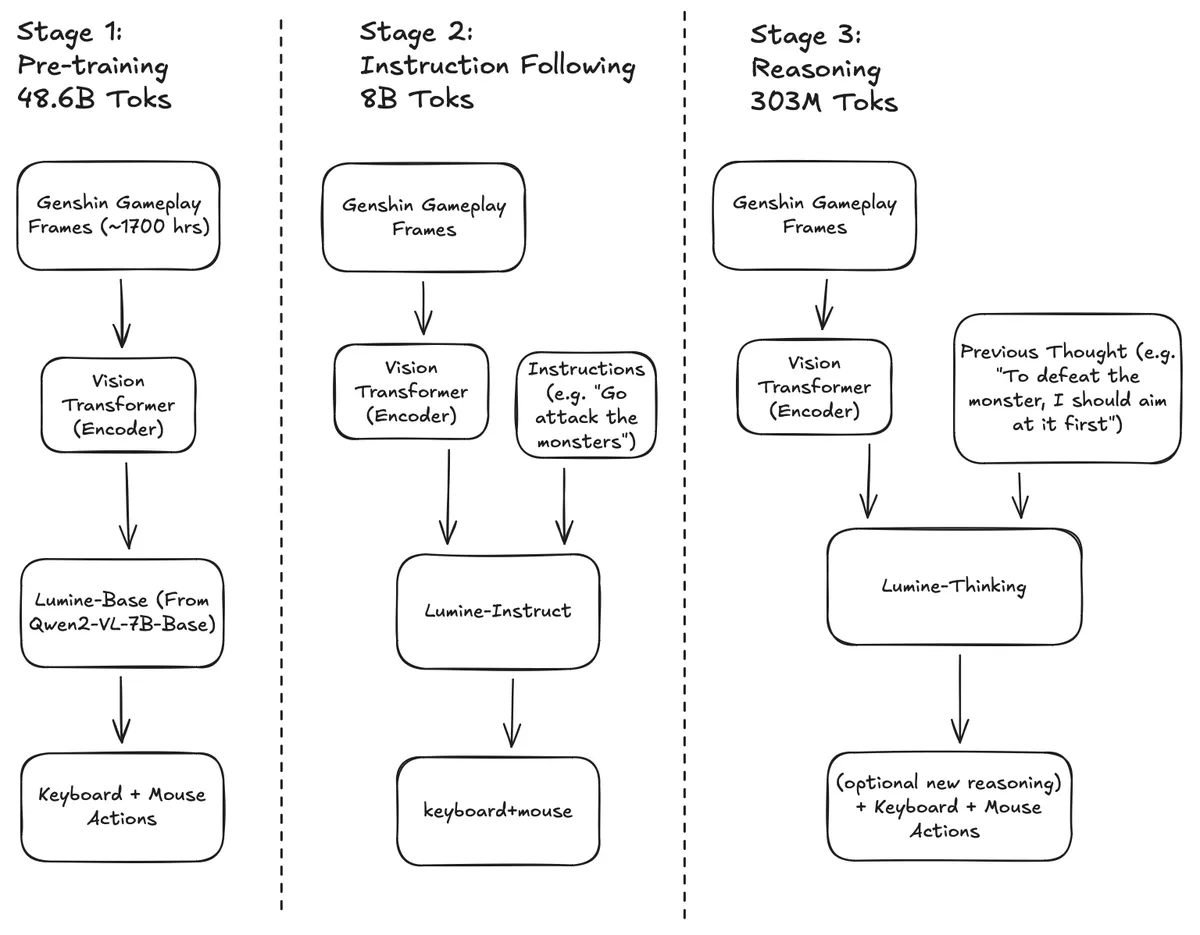 Figure 1: Lumine's three-stage training pipeline
Figure 1: Lumine's three-stage training pipeline
See Figure 1 for the training pipeline and Figure 2 for the context window structure.
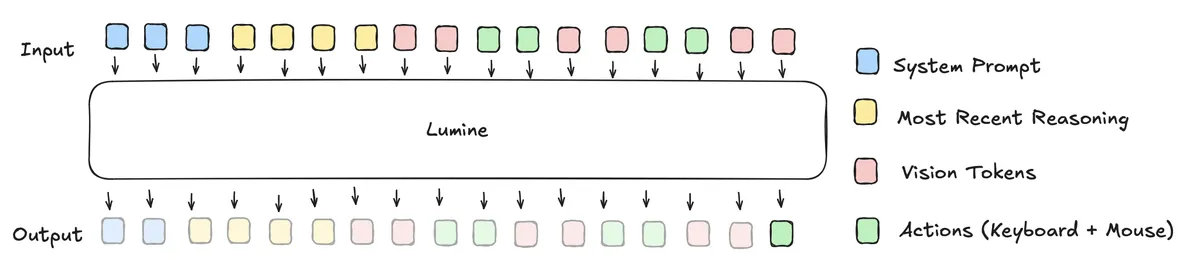 Figure 2: Context window structure showing perception-action token flow
Figure 2: Context window structure showing perception-action token flow
The context window management is interesting. It fills like this: system prompt at the start with broad instructions, then the most recent reasoning chain (containing goal-oriented information), then the rest fills sequentially with perception tokens (embedded screen pixels) paired with action tokens. When the context fills up, older perception-action pairs are evicted. When new reasoning is generated, the context flushes and old reasoning tokens are replaced, starting the process over. It's a neat system for managing goals and states naturally in a perception-in, action-out paradigm.
The real-time control relies on a stack of inference optimisations. They achieve a 25.3x overall speedup from a baseline of 3,655ms for a typical 20-token action sequence with a full 20-frame context. Using StreamingLLM, tensor parallelism, quantisation, speculative decoding, and infrastructure optimisations, they get the 20 action tokens down to ~130ms minimum.
What's Impressive
The standout result is the time horizon. Lumine completed 5 hours of main storyline missions in Genshin Impact – previous state of the art wasn't close. It achieved human expert-level completion times for the Act 1 Mondstadt mission (56 mins vs 53 expert vs 78 novice), though this mission was in both the pretraining and instruction data.
The generalisation impressed me most. It transferred skills like UI interaction, combat, puzzle solving, and world traversal to other games: Wuthering Waves, Honkai: Star Rail, and Black Myth: Wukong. These games have meaningful differences – one is turn-based, one has a realistic visual style, one is an ARPG with different mechanics. It's not clear if these games were in the web-scale base model data, but regardless, this level of generalisation to new contexts is notable. Within Genshin, it also showed skill transfer to unseen quests, like using platforming skills to reach new beacons.
Where It Breaks
The system has serious limitations.
The key one is the combination of reasoning quality and long-term memory. In a long-running rollout, it failed a later quest with multiple markers because it would face an obstacle, reason about getting around it, then get diverted in a cycle back to a different marker. It couldn't combine reasoning with persistent memory to stay focused on one goal before moving to another – getting stuck in a way a human or a system with proper long-term memory wouldn't. Earlier missions in the training data likely avoid this because the human annotators essentially handled the reasoning and memory functions.
Half of all errors were perception problems: mislabelling objects, misperceiving surroundings, misjudging distances. One near-catastrophic failure: the model accidentally turned off its quest markers, then when trying to turn them back on, misperceived that it had succeeded. This left it with reasoning traces saying "success" but visual input showing no markers. It wandered aimlessly for hours before eventually fixing the issue. A stronger VLM backbone would likely reduce these errors.
There's also a capability peak at 10 history frames – fewer or more (up to 20) decreases task completion rates. This might be attention saturation as the context fills, though it may not hold across different architectures.
What I'd Try
Multi-game training data. The model couldn't use the minimap or heal teammates – general skills it might learn from seeing them in other games. I'm reminded of Physical Intelligence's recent work showing VLA models generalise tasks between human and robot examples with enough data diversity. Training across games might help the model learn more abstract gaming concepts rather than Genshin-specific patterns.
Hierarchical memory. The current system keeps only one reasoning trace. A redesigned context window allowing multiple goals/subgoals, or a separate system using a stronger LLM to maintain a goal hierarchy, could help with the long-horizon failures. Even just smarter eviction with external summarisation might help.
Stronger base model. Given how many errors came from perception, a better VLM backbone should improve performance directly.
Scale. The 7B base is small for a model expected to handle perception, reasoning, and planning simultaneously. NVIDIA's NitroGen release has 10,000 hours of multi-game video and action data – tempting for scaling this approach. That said, the eval success rates were already plateauing by the several-thousand-hour mark, so I'd be most interested in architectural improvements that get more from the same data.
Technical Report: Lumine: An Open Recipe for Building Generalist Agents in 3D Open Worlds
Follow me on X @danrhuss